Gate-by-gate simulation is easy to implement, so our first stage is to implement the whole skeleton, including all components, the plugin engine, and the simulation engine. It has an obvious weak point: slow. We are now seeking a way to simulate a billion gates. We put our progress here. Here is our first attempt:
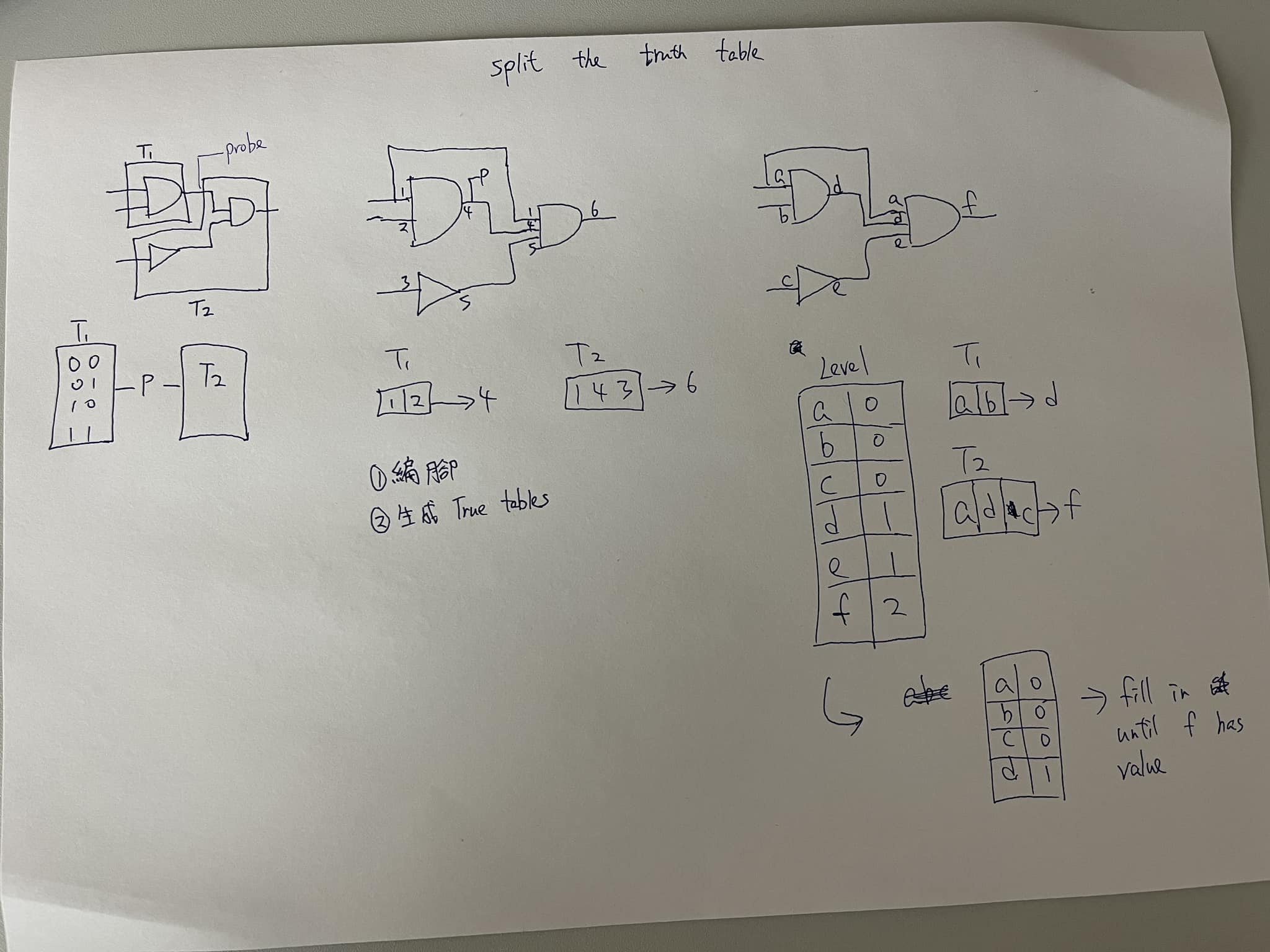
- We split the truth table and use RAM to direct output the result. Then the simulate no need to depend on the level of gate, it works much faster in most combinational circuits.
- We need to split the combinational circuit into piece and each piece work in similar duration, otherwise multithreading result will not be good, since some circuits take long time and some take short time to complete
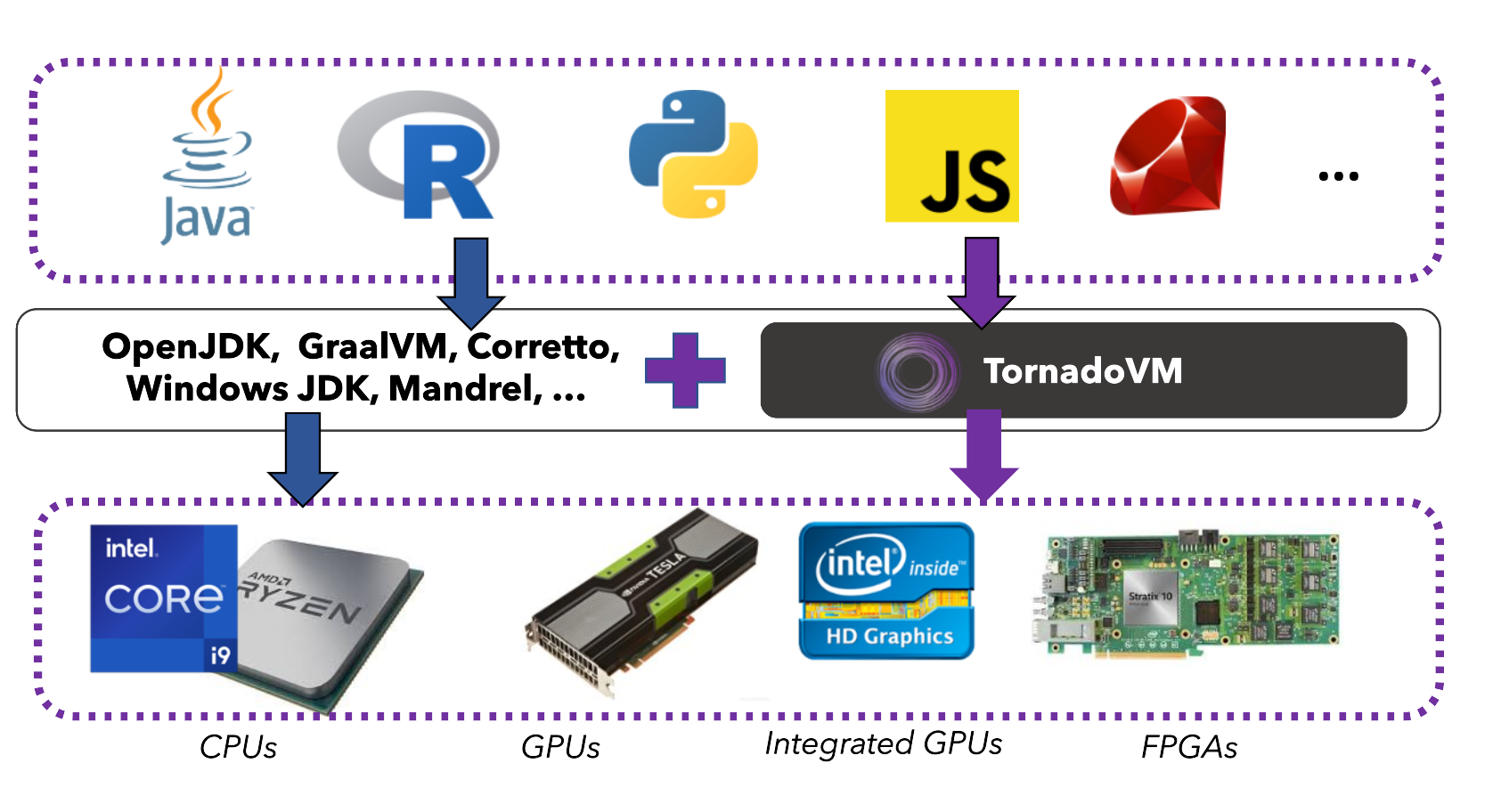
- We need to think of offloading the simulation in GPU or FPGA. FPGA will work faster but the programming model is much harder and lack of cross-platform ability
- Trying the Tornardo VM to offload some java to CUDA